
En pocas palabras, el Sistema de archivos interplanetarios es un protocolo de almacenamiento de archivos distribuido que permite que una red de computadoras almacene cualquier información arbitraria de una manera robusta e inmutable. Cada computadora en la red actúa como un cliente y un servidor, lo que le permite enrutar y almacenar en caché las solicitudes de red para otros clientes.
¿Por qué IPFS es tan especial?
El intercambio de archivos punto a punto ha existido durante años, ¿por qué IPFS es tan especial en este espacio? IPFS tiene algunas características útiles que lo hacen destacar en el espacio criptográfico, lo que lo convierte en la opción más popular y común para Internet descentralizado.
IPFS es inmutable: los datos, una vez agregados a la red, no se pueden cambiar. Los clientes pueden verificar que los datos que revisaron no se modificaron. Las actualizaciones se pueden publicar, pero estas tomarán la forma de nuevos archivos, nunca sobrescribiendo los antiguos.
IPFS es a prueba de duplicación: los datos se fragmentan y luego se almacenan y luego se codifican cuando se agregan a la red, lo que permite que los datos duplicados se asignen a los mismos nodos y, por lo tanto, solo se crea una entrada. Agregar un nuevo archivo a la red requerirá menos almacenamiento a medida que la red crece, suponiendo que el archivo sea relativamente similar a otros en la red.
IPFS está descentralizado: la red aún puede funcionar cuando los nodos se van y se unen. Se pueden desconectar grandes cantidades de nodos y todo el sistema seguirá siendo dependiente. Los intentos de eliminar información o censurar archivos no tendrán éxito sin la destrucción total de todos los nodos de la red.
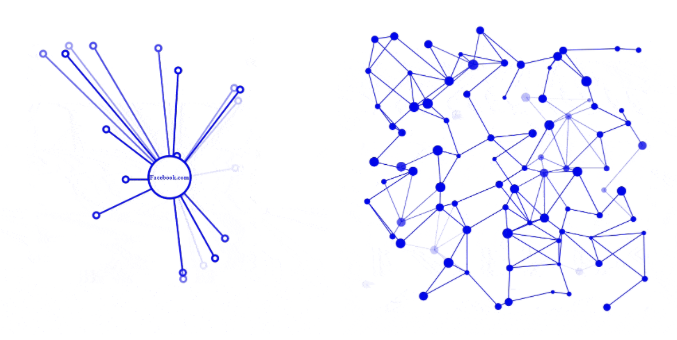
La característica clave aquí es la descentralización. Para ilustrar cómo se ve una red centralizada frente a una distribuida, hay algunas visualizaciones a continuación. La clave aquí es que, en efecto, Facebook controla la primera red, son la fuente absoluta de toda la verdad en la red. En la segunda red, cada nodo no es más importante que los demás.
Descripción general de IPFS
Antes de sumergirnos, establezcamos una descripción general de lo que IPFS hace debajo del capó. Como nodo en la red IPFS, establece conexiones con docenas de otros nodos en toda la red y actúa como un punto de enrutamiento para ellos. Usted llama a estos sus compañeros.
Dado que el contenido recibe un identificador único (un hash de 256 bits) y los clientes también reciben identificadores, toda la red puede formar un árbol. Cada nodo es un cliente o un contenido. Como cliente, mantiene un grupo de pares en forma de lista de exclusión. Conocer algunas personas del otro lado de la red (cuyas identificaciones son muy diferentes a las suyas) y muchas personas cercanas (cuyas identificaciones son muy similares).
Cuando solicite un contenido, ya sea porque lo desea o porque un muelle lo solicitó, puede dirigir su búsqueda a los muelles que conoce más cercanos a la identificación del contenido. En promedio, la solicitud convergerá en el tiempo Log(N). Además, en el viaje de regreso del contenido, cada nodo almacena en caché los datos para que las consultas futuras sean más rápidas. Dado que los datos nunca pueden cambiar, estos cachés son muy agresivos y ayudan a reducir los costos de la red.
Para luego acceder realmente al contenido almacenado, puede usar un nodo que se ejecuta localmente o enrutar a través de un nodo existente pasándole la ID de contenido. Ipfs.io ejecuta su propio nodo, pruebe este enlace para ver ipfs en acción:
Cómo se almacena el contenido en IPFS
A continuación, veamos cómo IPFS almacenará un archivo específico en la red. En primer lugar, debemos ejecutar un nodo IPFS. Aunque IPFS se distribuye, eso no significa que sea gratuito. Para cada archivo alojado, alguien tiene que ser el primer nodo en alojarlo. Si es lo suficientemente popular, otros nodos lo almacenarán en caché y ayudarán a transmitirlo, pero debe comenzar en alguna parte. Si un archivo está anclado, se garantiza que estará disponible en la red; si no está anclado, continuará sobreviviendo hasta que se caiga del caché del sistema. Puede pagar a las personas para que anclen su archivo, pero por el bien de este ejemplo, supongamos que lo está haciendo usted mismo.
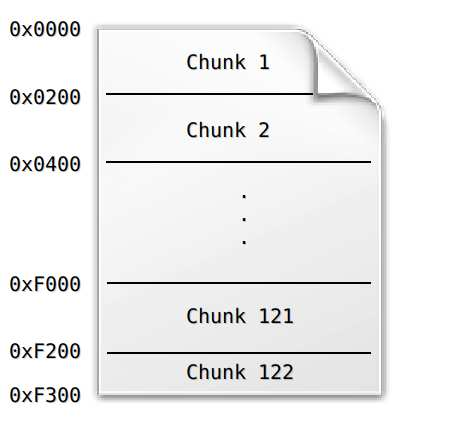
Antes de fijar, el archivo se divide primero en fragmentos de tamaño definido (256 KB). Luego, cada fragmento se codifica individualmente, generando un identificador único para cada fragmento en algún rango (0 a 2²⁵⁶). Usando un árbol de Merkle, estos hash se combinan para generar un hash para todo el archivo. Este hash es el ID de contenido para ese archivo.
Ahora necesitamos codificar cada fragmento en la red. Simplemente recorra la red para cada fragmento y encuentre un vecindario de clientes que estén más cerca de cada fragmento (comparando la ID del fragmento y la ID del cliente), informándoles que usted es una fuente para los datos proporcionados. Cuando reciben solicitudes de los datos de destino, pueden acudir a usted ahora.
Fijación
Antes de fijar, el archivo se divide primero en fragmentos de tamaño definido (256 KB). Luego, cada fragmento se codifica individualmente, generando un identificador único para cada fragmento en algún rango (0 a 2²⁵⁶). Usando un árbol de Merkle, estos hash se combinan para generar un hash para todo el archivo. Este hash es el ID de contenido para ese archivo.
Ahora necesitamos codificar cada fragmento en la red. Simplemente recorra la red para cada fragmento y encuentre un vecindario de clientes que estén más cerca de cada fragmento (comparando la ID del fragmento y la ID del cliente), informándoles que usted es una fuente para los datos proporcionados. Cuando reciben solicitudes de los datos de destino, pueden acudir a usted ahora.